您好,欢迎进入江南娱乐手机客户端 官方网站!


Flash名称的由来,Flash的擦除操作是以block块为单位的,与此相对应的是其他很多存储设备,是以bit位为最小读取/写入的单位,Flash是一次性地擦除整个块:在发送一个擦除命令后,一次性地将一个block,常见的块的大小是128KB/256KB,全部擦除为1,也就是里面的内容全部都是0xFF了,由于是一下子就擦除了,相对来说,擦除用的时间很短,可以用一闪而过来形容,所以,叫做Flash Memory。所以一般将Flash翻译为 (快速)闪存。
NAND Flash 在嵌入式系统中有着广泛的应用,负载平均和坏块管理是与之相关的两个核心议题。Uboot 和 Linux 系统对 NAND 的操作都封装了对这两个问题的处理方法。 本文首先讲述Nandflash基础知识,然后介绍现有的几类坏块管理(BBM)方法,通过分析典型嵌入式系统的 NAND 存储表,指出了轻量级管理方法的优势所在,分析了当前广泛使用的轻量级管理方法,指出其缺陷所在并详细说明了改进方法。
基础知识
Flash的硬件实现机制
Flash的内部存储是MOSFET,里面有个悬浮门(Floating Gate),是真正存储数据的单元。
在Flash之前,紫外线可擦除(uv-erasable)的EPROM,就已经采用了Floating Gate存储数据这一技术了。
典型的Flash内存物理结构 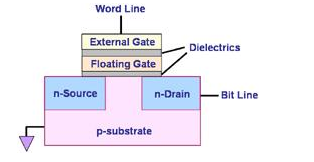
数据在Flash内存单元中是以电荷(electrical charge) 形式存储的。存储电荷的多少,取决于图中的外部门(external gate)所被施加的电压,其控制了是向存储单元中冲入电荷还是使其释放电荷。而数据的表示,以所存储的电荷的电压是否超过一个特定的阈值Vth来表示,因此,Flash的存储单元的默认值,不是0(其他常见的存储设备,比如硬盘灯,默认值为0),而是1,而如果将电荷释放掉,电压降低到一定程度,表述数字0。
NandFlash的简介
Nand flash成本相对低,说白了就是便宜,缺点是使用中数据读写容易出错,所以一般都需要有对应的软件或者硬件的数据校验算法,统称为ECC。但优点是,相对来说容量比较大,现在常见的Nand Flash都是1GB,2GB,更大的8GB的都有了,相对来说,价格便宜,因此适合用来存储大量的数据。其在嵌入式系统中的作用,相当于PC上的硬盘,用于存储大量数据。
SLC和MLC
Nand Flash按照内部存储数据单元的电压的不同层次,也就是单个内存单元中,是存储1位数据,还是多位数据,可以分为SLC和MLC。那么软件如何识别系统上使用过的SLC还是MLC呢?
Nand Flash设计中,有个命令叫做Read ID,读取ID,读取好几个字节,一般最少是4个,新的芯片,支持5个甚至更多,从这些字节中,可以解析出很多相关的信息,比如此Nand Flash内部是几个芯片(chip)所组成的,每个chip包含了几片(Plane),每一片中的页大小,块大小,等等。在这些信息中,其中有一个,就是识别此flash是SLC还是MLC。
oob / Redundant Area / Spare Area
每一个页,对应还有一块区域,叫做空闲区域(spare area)/冗余区域(redundant area),而Linux系统中,一般叫做OOB(Out Of Band),这个区域,是最初基于Nand Flash的硬件特性:数据在读写时候相对容易错误,所以为了保证数据的正确性,必须要有对应的检测和纠错机制,此机制被叫做EDC(Error Detection Code)/ECC(Error Code Correction, 或者 Error Checking and Correcting),所以设计了多余的区域,用于放置数据的校验值。
Oob的读写操作,一般是随着页的操作一起完成的,即读写页的时候,对应地就读写了oob。
关于oob具体用途,总结起来有:
- 标记是否是坏快
- 存储ECC数据
- 存储一些和文件系统相关的数据。如jffs2就会用到这些空间存储一些特定信息,而yaffs2文件系统,会在oob中,存放很多和自己文件系统相关的信息。
Bad Block Management坏块管理
Nand Flash由于其物理特性,只有有限的擦写次数,超过那个次数,基本上就是坏了。在使用过程中,有些Nand Flash的block会出现被用坏了,当发现了,要及时将此block标注为坏块,不再使用。于此相关的管理工作,属于Nand Flash的坏块管理的一部分工作。
Wear-Leveling负载平衡
Nand Flash的block管理,还包括负载平衡。
正是由于Nand Flash的block,都是有一定寿命限制的,所以如果你每次都往同一个block擦除然后写入数据,那么那个block就很容易被用坏了,所以我们要去管理一下,将这么多次的对同一个block的操作,平均分布到其他一些block上面,使得在block的使用上,相对较平均,这样相对来说,可以更能充分利用Nand Flash。
ECC错误校验码
Nand Flash物理特性上使得其数据读写过程中会发生一定几率的错误,所以要有个对应的错误检测和纠正的机制,于是才有此ECC,用于数据错误的检测与纠正。Nand Flash的ECC,常见的算法有海明码和BCH,这类算法的实现,可以是软件也可以是硬件。不同系统,根据自己的需求,采用对应的软件或者是硬件。
相对来说,硬件实现这类ECC算法,肯定要比软件速度要快,但是多加了对应的硬件部分,所以成本相对要高些。如果系统对于性能要求不是很高,那么可以采用软件实现这类ECC算法,但是由于增加了数据读取和写入前后要做的数据错误检测和纠错,所以性能相对要降低一些,即Nand Flash的读取和写入速度相对会有所影响。
其中,Linux中的软件实现ECC算法,即NAND_ECC_SOFT模式,就是用的对应的海明码。
而对于目前常见的MLC的Nand Flash来说,由于容量比较大,动辄2GB,4GB,8GB等,常用BCH算法。BCH算法,相对来说,算法比较复杂。
笔者由于水平有限,目前仍未完全搞懂BCH算法的原理。
BCH算法,通常是由对应的Nand Flash的Controller中,包含对应的硬件BCH ECC模块,实现了BCH算法,而作为软件方面,需要在读取数据后,写入数据之前,分别操作对应BCH相关的寄存器,设置成BCH模式,然后读取对应的BCH状态寄存器,得知是否有错误,和生成的BCH校验码,用于写入。
其具体代码是如何操作这些寄存器的,由于是和具体的硬件,具体的nand flash的controller不同而不同,无法用同一的代码。如果你是nand flash驱动开发者,自然会得到对应的起nand flash的controller部分的datasheet,按照手册说明,去操作即可。
不过,额外说明一下的是,关于BCH算法,往往是要从专门的做软件算法的厂家购买的,但是Micron之前在网上放出一个免费版本的BCH算法。
位反转
Nand Flash的位反转现象,主要是由以下一些原因/效应所导致:
- 漂移效应(Drifting Effects)
漂移效应指的是,Nand Flash中cell的电压值,慢慢地变了,变的和原始值不一样了。
- 编程干扰所产生的错误(Program-Disturb Errors)
此现象有时候也叫做,过度编程效应(over-program effect)。
对于某个页面的编程操作,即写操作,引起非相关的其他的页面的某个位跳变了。
- 读操作干扰产生的错误(Read-Disturb Errors)
此效应是,对一个页进行数据读取操作,却使得对应的某个位的数据,产生了永久性的变化,即Nand Flash上的该位的值变了。
对应位反转的类型,Nand Flash位反转的类型和解决办法,有两种:
- 一种是nand flash物理上的数据存储的单元上的数据,是正确的,只是在读取此数据出来的数据中的某位,发生变化,出现了位反转,即读取出来的数据中,某位错了,本来是0变成1,或者本来是1变成0了。此处可以成为软件上位反转。此数据位的错误,当然可以通过一定的校验算法检测并纠正。
- 另外一种,就是nand flash中的物理存储单元中,对应的某个位,物理上发生了变化,原来是1的,变成了0,或原来是0的,变成了1,发生了物理上的位的数据变化。此处可以成为硬件上的位反转。此错误,由于是物理上发生的,虽然读取出来的数据的错误,可以通过软件或硬件去检测并纠正过来,但是物理上真正发生的位的变化,则没办法改变了。不过个人理解,好像也是可以通过擦除Erase整个数据块Block的方式去擦除此错误,不过在之后的Nand Flash的使用过程中,估计此位还是很可能继续发生同样的硬件的位反转的错误。
以上两种类型的位反转,其实对于从Nand Flash读取出来的数据来说,解决其中的错误的位的方法,都是一样的,即通过一定的校验算法,常称为ECC,去检测出来,或检测并纠正错误。
如果只是单独检测错误,那么如果发现数据有误,那么再重新读取一次即可。
实际中更多的做法是,ECC校验发现有错误,会有对应的算法去找出哪位错误并且纠正过来。
其中对错误的检测和纠正,具体的实现方式,有软件算法,也有硬件实现,即硬件Nand Flash的控制器controller本身包含对应的硬件模块以实现数据的校验和纠错的。

Nand Flash的一些typical特性
- 页擦除时间是200us,有些慢的有800us
- 块擦除时间是1.5ms
- 页数据读取到数据寄存器的时间一般是20us
- 串行访问(Serial access)读取一个数据的时间是25ns,而一些旧的Nand Flash是30ns,甚至是50ns
- 输入输出端口是地址和数据以及命令一起multiplex复用的
- Nand Flash的编程/擦除的寿命:即,最多允许10万次的编程/擦除,达到和接近于之前常见的Nor Flash,几乎是同样的使用寿命了。
- 封装形式:48引脚的TSOP1封装 或 52引脚的ULGA封装
Nand Flash控制器与Nand Flash芯片
我们写驱动,是写Nand Flash 控制器的驱动,而不是Nand Flash 芯片的驱动,因为独立的Nand Flash芯片,一般来说,是很少直接拿来用的,多数都是硬件上有对应的硬件的Nand Flash的控制器,去操作和控制Nand Flash,包括提供时钟信号,提供硬件ECC校验等等功能,我们所写的驱动软件,是去操作Nand Flash的控制器
然后由控制器去操作Nand Flash芯片,实现我们所要的功能。
由于Nand Flash读取和编程操作来说,一般最小单位是页,所以Nand Flash在硬件设计时候,就考虑到这一特性,对于每一片(Plane),都有一个对应的区域专门用于存放,将要写入到物理存储单元中去的或者刚从存储单元中读取出来的,一页的数据,这个数据缓存区,本质上就是一个缓存buffer,但是只是此处datasheet里面把其叫做页寄存器page register而已,实际将其理解为页缓存,更贴切原意。
而正是因为有些人不了解此内部结构,才容易产生之前遇到的某人的误解,以为内存里面的数据,通过Nand Flash的FIFO,写入到Nand Flash里面去,就以为立刻实现了实际数据写入到物理存储单元中了,而实际上只是写到了这个页缓存中,只有当你再发送了对应的编程第二阶段的确认命令,即0x10,之后,实际的编程动作才开始,才开始把页缓存中的数据,一点点写到物理存储单元中去。
坏块的标记
具体标记的地方是,对于现在常见的页大小为2K的Nand Flash,是块中第一个页的oob起始位置的第1个字节(旧的小页面,pagesize是512B甚至256B的Nand Flash,坏块标记是第6个字节),如果不是0xFF,就说明是坏块。相对应的是,所有正常的块,好的块,里面所有数据都是0xFF的。
对于坏块的标记,本质上,也只是对应的flash上的某些字节的数据是非0xFF而已,所以,只要是数据,就是可以读取和写入的。也就意味着,可以写入其他值,也就把这个坏块标记信息破坏了。对于出厂时的坏块,一般是不建议将标记好的信息擦除掉的。
uboot中有个命令是
nand scrub
就可以将块中所有的内容都擦除了,包括坏块标记,不论是出厂时的,还是后来使用过程中出现而新标记的。
nand erase
只擦除好的块,对于已经标记坏块的块,不要轻易擦除掉,否则就很难区分哪些是出厂时就坏的,哪些是后来使用过程中用坏的了。
Uboot 的轻量级坏块管理方法
NAND 坏块管理都是基于坏块表(BBT)的,通过这张表来标识系统中的所有坏块。所以,不同的管理方法之间的差异可以通过以下几个问题来找到答案。
- 如何初始化和读取坏块表?
- 产生新的坏块时,如何标记并更新坏块表?
- 如何保存坏块表?是否有保存时断电保护机制?
- 对 NAND 写入数据时,如果当前块是坏块,如何找到可替换的好块?
Uboot 是目前使用最为广泛的 bootloader,它提供了两种轻量级坏块管理方法,可称之为基本型和改进型。通过下表,我们可以看到两者的差异。

虽然 uboot 的改进型坏块管理方法的做了一些改进,但它仍然有三个主要的缺点。
- 出现坏块,则将数据顺序写入下一个好块。如果 NAND 中存放了多个软件模块,则每个模块都需要预留一个较大的空间作为备用的好块,这会浪费较多的 NAND 空间。通常,每个模块预留的备用好块数为 NAND 芯片所允许的最大坏块数,该值因不同的芯片而有所不同,典型值为 20 或 80。假设 NAND 是大页类型,总共有 N 个模块,则总共需要预留的空间大小为 N*80*128KB。
- 读取 BBT 时仅检查签名,没有对 BBT 的数据做校验。
- 没有掉电保护机制。如果在保存 BBT 时断电,BBT 将丢失。
针对现有管理方法的缺陷,本文提出了一种更加安全高效的管理方法,将从以下三个方面阐述其实现原理。
共用好块池机制
首先,使用一个统一的备用好块池,为所有存放在 NAND 中的模块提供可替换的好块。这样,就不需要在每个模块后面放置一个保留区,提高了 NAND 的空间利用率。
共用好块池示意图
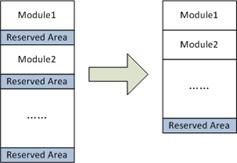
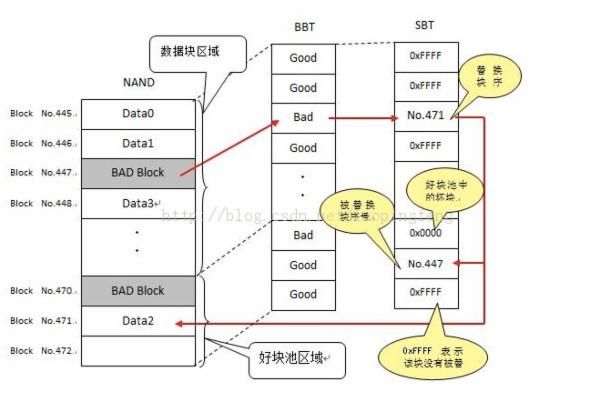
为了实现共用好块池,需要建立一个从坏块到好块的映射,所以,除了 BBT 之外,还需定义一个替换表(SBT)。这样一来,当读第 i 个块的数据时,如果发现 BBT 中记录该块为坏块,就去 SBT 中查询其替换块;如果写第 i 个块出错,需要在 BBT 中标记该块为坏块,同时从好块池中获取一个新的好块,假设其序号为 j,然后将此好块的序号 j 写入 SBT 中的第 i 个字节,而且 SBT 的第 j 个字节写序号 i。SBT 中的这种双向映射可确保数据的可靠性。此外,好块池中的块也有可能成为坏块,如果扫描时发现是坏块,则将 SBT 中的对应位置标记为 0x00,如果是在写的过程中出错,则除了在 SBT 对应位置标记 0x00 之外,还要更新双向映射数据。
BBT/SBT 映射示意图
安全的 BBT/SBT 数据校验机制
传统方法仅检查 BBT 所在块的签名,将读到的前几个字节和一个特征字符串进行比较,如果一致,就认为当前块的数据为 BBT,然后读取接下来的 BBT 数据,但并不对 BBT 的数据做校验。如果 BBT 保存在 NAND 中,数据的有效性是可以得到验证的,因为 NAND 控制器或驱动一般都会对数据做 ECC 校验。但是,大多数控制器使用的 ECC 算法也仅仅能纠正一个 bit、发现 2 两个 bit 的错误。如果 BBT 保存在其他的没有 ECC 校验机制的存储体中,比如 NOR Flash,没有对 BBT 的数据进行校验显然是不安全的。
为了更加可靠和灵活地验证 BBT/SBT 数据,定义下面这个结构体来描述 BBM 信息。
BBM 头信息
typedef struct {
UINT8 acSignature[4];/* BBM 签名 */
UINT32 ulBBToffset;/* BBT 偏移 */
UINT32 ulSBToffset;/* SBT 偏移 */
UINT16 usBlockNum;/* BBM 管理的 block 数目 */
UINT16 usSBTstart;/* SBT 所在位置的起始 block 序号 */
UINT16 usSBtop;/* SBT top block */
UINT16 usSBnum;/* SBT number */
UINT32 ulBBTcrc;/* BBT 数据 CRC 校验码 */
UINT32 ulSBTcrc;/* SBT 数据 CRC 校验码 */
UINT32 ulHeadcrc;/* BBM 头信息 CRC 校验码 */
} BBM_HEADBBT/SBT 的保存形式

使用三重 CRC 校验机制,无论 BBT 保存在哪种存储体中,都可以更加严格地验证数据的有效性。
安全的掉电保存机制
传统的方法仅保存一份 BBT 数据,如果在写 BBT 时系统掉电,则 BBT 丢失,系统将可能无法正常启动或工作。为安全起见,本文所述方法将同时保留三个备份,如果在写某个备份时掉电,则还有两个完好的备份。最坏的情况是,如果在写第一个备份时掉电,则当前最新的一个坏块信息丢失。
读取坏块表时,顺序读取三个备份,如果发现三个备份的数据不一致,用记录的坏块数最多的备份为当前的有效备份,同时立刻更新另外两备份。
总结
本文介绍了NandFlash基础知识和几类 NAND 坏块管理方法,指出了 uboot 的轻量级管理方法的缺陷,提出了一种改进的方法,提高了 NAND 的利用率及坏块管理的安全性,可对嵌入式开发起到有很好的借鉴作用。
ECC定义
ECC校验是一种内存纠错原理,它是比较先进的内存错误检查和更正的手段。ECC内存即纠错内存,简单的说,其具有发现错误,纠正错误的功能,一般多应用在高档台式电脑/服务器及图形工作站上,这将使整个电脑系统在工作时更趋于安全稳定。
技术原理
内存是一种电子器件,在其工作过程中难免会出现错误,而对于稳定性要求高的用户来说,内存错误可能会引起致命性的问题。内存错误根据其原因还可分为硬错误和软错误。硬件错误是由于硬件的损害或缺陷造成的,因此数据总是不正确,此类错误是无法纠正的;软错误是随机出现的,例如在内存附近突然出现电子干扰等因素都可能造成内存软错误的发生。
为了能检测和纠正内存软错误,在ECC技术出现之前,首先出现的是内存“奇偶校验(Parity)”。内存中最小的单位是比特,也称为“位(bit)”,位有只有两种状态分别以1和0来标示,每8个连续的比特叫做一个字节(byte)。不带奇偶校验的内存每个字节只有8位,如果其某一位存储了错误的值,就会导致其存储的相应数据发生变化,进而导致应用程序发生错误。而奇偶校验就是在每一字节(8位)之外又增加了一位作为错误检测位。在某字节中存储数据之后,在其8个位上存储的数据是固定的,因为位只能有两种状态1或0,假设存储的数据用位标示为1、1、1、0、0、1、0、1,那么把每个位相加(1+1+1+0+0+1+0+1=5),结果是奇数。对于偶校验,校验位就定义为1,反之则为0;对于奇校验,则相反。当CPU读取存储的数据时,它会再次把前8位中存储的数据相加,计算结果是否与校验位相一致。从而一定程度上能检测出内存错误,奇偶校验只能检测出错误而无法对其进行修正,同时虽然双位同时发生错误的概率相当低,奇偶校验却无法检测出双位错误。
通过上面的分析我们知道Parity内存是通过在原来数据位的基础上增加一个数据位来检查当前8位数据的正确性,但随着数据位的增加Parity用来检验的数据位也成倍增加,就是说当数据位为16位时它需要增加2位用于检查,当数据位为32位时则需增加4位,依此类推。特别是当数据量非常大时,数据出错的几率也就越大,对于只能纠正简单错误的奇偶检验的方法就显得力不从心了,正是基于这样一种情况,一种新的内存技术应允而生了,这就是ECC(错误检查和纠正),这种技术也是在原来的数据位上外加校验位来实现的。不同的是两者增加的方法不一样,这也就导致了两者的主要功能不太一样。它与Parity不同的是如果数据位是8位,则需要增加5位来进行ECC错误检查和纠正,数据位每增加一倍,ECC只增加一位检验位,也就是说当数据位为16位时ECC位为6位,32位时ECC位为7位,数据位为64位时ECC位为8位,依此类推,数据位每增加一倍,ECC位只增加一位。总之,在内存中ECC能够容许错误,并可以将错误更正,使系统得以持续正常的操作,不致因错误而中断,且ECC具有自动更正的能力,可以将Parity无法检查出来的错误位查出并将错误修正。
示例
ECC(Error Checking and Correcting,错误检查和纠正)内存,它同样也是在数据位上额外的位存储一个用数据加密的代码。当数据被写入内存,相应的ECC代码与此同时也被保存下来。当重新读回刚才存储的数据时,保存下来的ECC代码就会和读数据时产生的ECC代码做比较。如果两个代码不相同,他们则会被解码,以确定数据中的哪一位是不正确的。然后这一错误位会被抛弃,内存控制器则会释放出正确的数据。被纠正的数据很少会被放回内存。假如相同的错误数据再次被读出,则纠正过程再次被执行。重写数据会增加处理过程的开销,这样则会导致系统性能的明显降低。如果是随机事件而非内存的缺点产生的错误,则这一内存地址的错误数据会被再次写入的其他数据所取代。
上一篇:Linux 系统目录结构





